There is a New Type of Memory (EFAM) in Town Part 2 of 2
Monday April 13, 2020By Mark Baumann Director
Product Definition & Applications
MoSys, Inc.
In Part 1 of this blog, we discussed the legacy of memory and how its growth and development tracked closely to Moore’s Law. We also reviewed the differences between a DRAM and DRAM-based device versus MoSys BE devices. In Part 2 of this blog, we will get into the details of EFAM, Embedded Function Accelerator Memory.
EFAM (Embedded Function Accelerator Memory)
When reviewing the common memories used in both networking systems and indeed many systems, there is a need of some portion of the memory to be of high random-access rate and low latency. Whether it is for table lookups, high frequency trading or just to be able to store and forward at the prevailing line rate. It is not uncommon for multiple accesses on the data to perform some form of manipulation while the data is being transported through the system. In this case the additional functionality, supported by the MoSys devices become an even greater advantage, as the MoSys devices have progressed, by adding additional functionality or acceleration. The goal behind the functions is to accelerate what are felt to be very common and time intensive operations. The following are the functions that are presently available in MoSys Accelerator Engine devices:
BURST
The first being a burst operation. The benefit of this operation is straight forward, in that it allows the user to burst data both in and out of the Accelerator Engines. This function allows the user to burst 2, 4, or 8 words (72bits each) with only one command being issued. In these applications no decisions need to be made on the data it just need to be stored and eventually forwarded.
R-M-W
Read – Modify – Write. This too is a function, and when executed, is very time intensive. Again in support of a common time intensive operation, the Accelerator Engines have taken a common operation which in its sub components is a Read operation, A Modify operation and a Write operation and made it a single command with a “fire-and-forget” construct in which the operand is sent with the data modifier and the Accelerator engine will internally perform this operation Atomically to insure that data will not be corrupted or lost even if multiple operations to the same data location are requested. The available operations are as follows:
- Boolean
- AND, OR, XOR memory location with a 16b or 32b mask
- Arithmetic for statistics functions
- Add/Subtract 16b or 32b immediate
- Read and Set 16b, 32b, 64b & double
- Add 1 to packet and 16b or 32b immediate to byte count
- Decrement Age Count of packet/byte counter pair
- Semaphores and Mutex for real-time multi-thread table updates
- Test for Zero and Set on 16b, 32b, & 64b
- Compare and Exchange on 32b
- Specialized counting functions
- Compute running average 16b values
- Compute metering (leaky bucket, 3 color, two rates) for policing and shaping
The above list of operations are designed to support data statistics, metering and basic decision functions like aging. All of which take place with a single command being issued.
Programmable Functions
The latest in the family of Accelerator engines is the Programmable HyperSpeed Engine (PHE). In this device, the functionality that is made available include the Burst and R-M-W of the previous devices, as well as adding 32 processor Engines (RISC Cores), each engine is possible to be up to 8 way threaded, each of which has the ability to access all the resources of memory and registers. This provides a large step up in both performance and functionality by providing the user the capability to design and build a custom algorithm or feature set that runs at the internal core rate of up to 1.5GHz. This provides the ultimate in flexibility and performance in allowing you as a designer a clean slate to differentiate the functionality offered in your system.
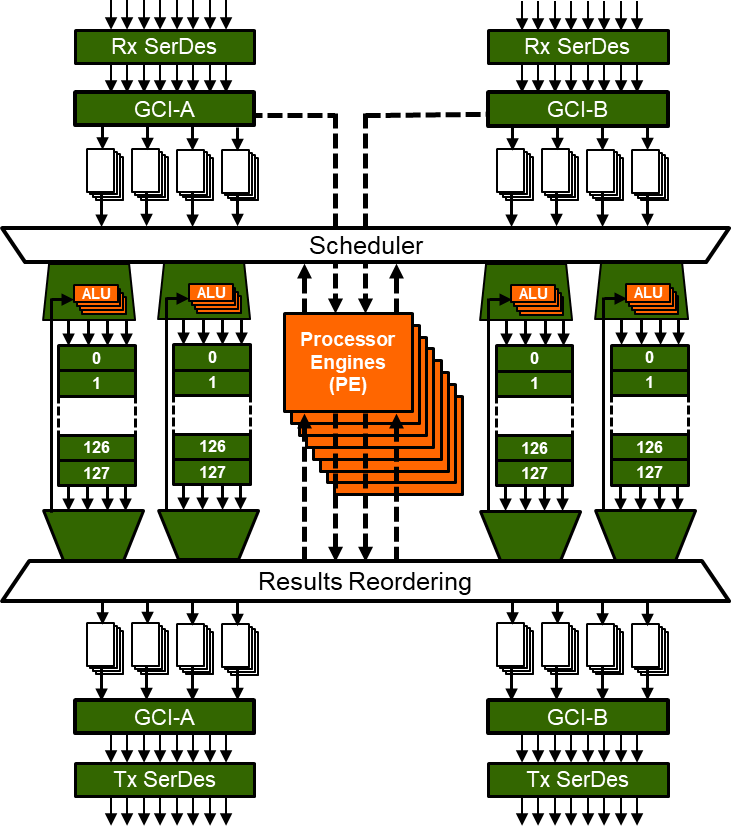
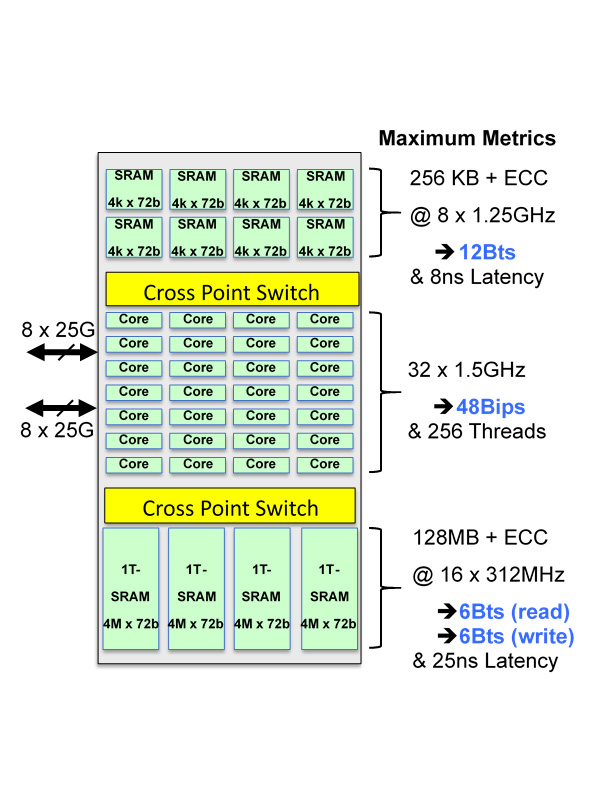
- Large Capacity Data Structure
- 128MB + ECC
- Parallel expansion
- Tightly Coupled Cores & Memory
- Direct connect via cross point Switch
- No cache è no miss variability
- Optimized Instruction Set
- Hash, Compressed Trie etc.
- Packed bit fields
- 24b x 24b Multiplier
- High Parallelism
- Up to 8 way thread cores
- 8 way threaded SRAM
- 16 way Thread 1T-SRAM
- Low Latency Memory Access
- 6ns to 25ns
- 4x faster than DRAM
- 2 Level hierarchy possible
Additional Resources:
If you are looking for more technical information or need to discuss your technical challenges with an expert, we are happy to help. Email us and we will arrange to have one of our technical specialists speak with you. You can also sign up for updates. Finally, please follow us on social media so we can keep in touch.


