Supporting 4 x 100GE TCAM vs Algorithm-Based Solution Use GME
Thursday March 19, 2020By Michael Miller
Chief Technology Officer, MoSys, Inc.
It is true that a TCAM can perform 600Mlps or more on 600+ bit search keys using 16 to 24 x 25G SerDes. The results will be returned in a deterministic latency of ~400ns. Some applications may truly require this kind of performance, but that choice comes with a real cost in money and power. Power varies greatly (75W to 150W) with search patterns and data set size. TCAMs are sole sourced and not well supported. Finally, the largest TCAM’s capacity is finite at 80Mb which means 2M IPv4 or 128K ACL rules. And what if you need to scale to more? Many of today’s applications do not need this absolute performance and may desire larger table sizes. For these reasons, algorithms supported by highspeed memory provide a better alternative when size and flexibility count. So, what performance level can algorithmic solutions provide?
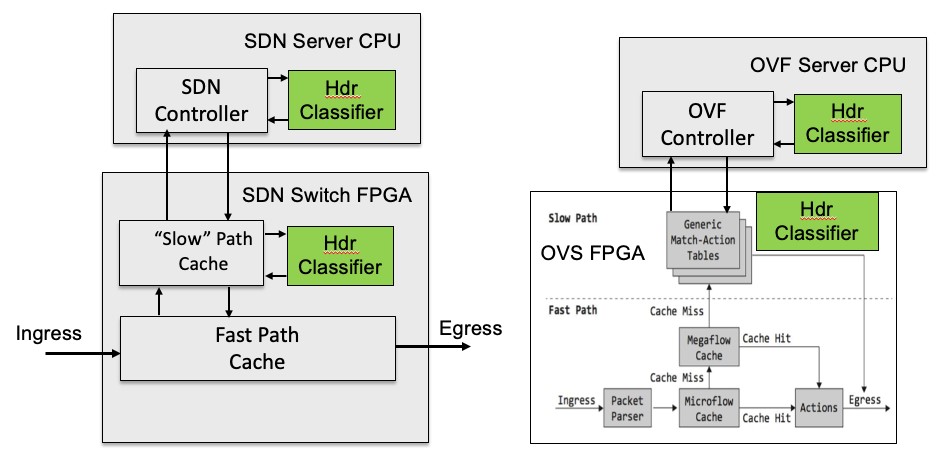
Many of todays’ packet switching and routing designs use flow caches for the microburst of packets utilizing the same header and graph-based algorithms that are used for various types of searches. The Longest Prefix Matches, for example, use Mtrie which are basically radix trees. This approach has been used for more than a decade. The advantage here is that large tables of ~1M can be accommodated. The downside is that the latency can be variable. But this is mitigated with the flow cache. For the odd packet where the answer does not come back fast enough and the packet was dropped, the flow cache will remember it later. Open vSwitch (OVS) is an example of such a hierarchical structure. In this case, flows are broken into “Microflows” and “Megaflows”. In other systems this may be just one cache.
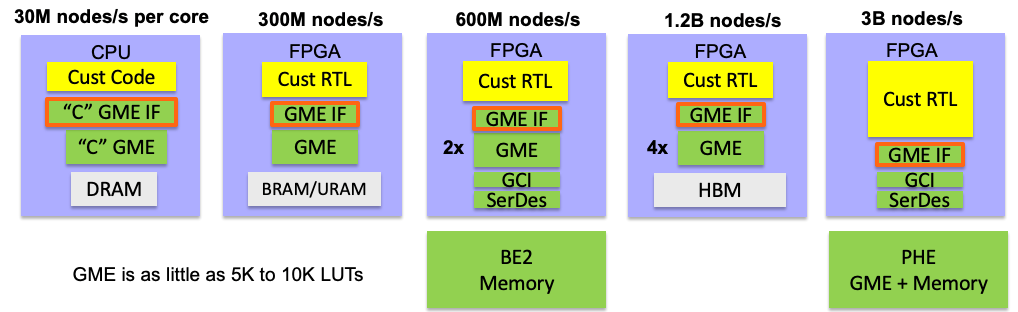
Multi-field matches that use graph-based algorithm approaches can take longer than a TCAM. The depth of the graph determines the maximum latency. The maximum latency is therefore determined like a Finite State Machine (FSM) where the memory access latency plays a major role in the time to move from one node to the next. The number of packets per second is often expressed as Millions of Lookups per Second (Mlps). The lookup rate for a graph engine is therefore the maximum memory access rate divided by the average graph depth. For example, 3B nodes per second divided by 10 nodes is 300Mlps.
But what does this mean in a world of multiple 100GE links where each can be as much as 150Mpps? We could assume that for 4 x 100GE we would need 600Mllps which would take us back to where we started, needing a TCAM. But, as we discussed, the flow cache can reduce that requirement greatly. And is 600Mlps even the real number?
Turns out, the 150Mlps number comes from benchmarks that assumed the smallest packet of 64B. This most likely came about because the Ping mechanism could be used to see how well a system performed. But if a network were only transporting 64B packets there would be no data moving in the network. This means zero percent network throughput. Zip data.
Moreover, real network applications try to make use of the Maximum Transfer Unit (MTU) sized packet for networks which means >1000 bytes per data frame. This is true of webpage downloads using TCP as well as Realtime streaming video data using UDP. So, what does that look like?
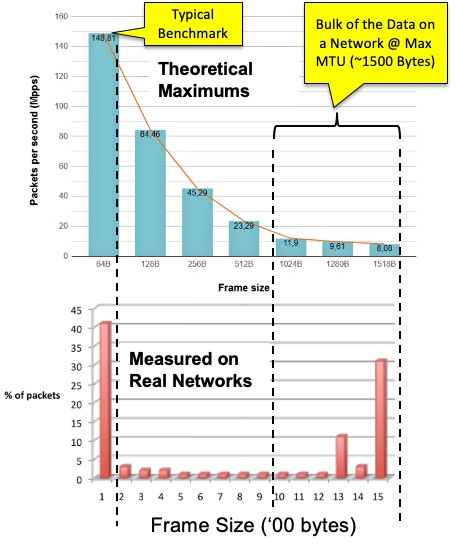
If we assume that most data packets are >1000 bytes, then that means 12Mpps for the data for 100GE. Add in acknowledgement packets (one for every data frame) and that takes us to 24Mpps for TCP/IP. The conclusion is that for 4 x 100GE, 100Mlps should be enough. This means that a graph engine of 3B nodes/s graphs of 30 nodes could be supported even without caches!
What about latency? Today, most algorithms will divide the graph database into multiple graphs and divide up the problematic groups of rules which need deep searches into separate trees. The graphs can be searched in parallel to reduce the latency to final result.
But wait, you say, what about a search key size of ~600 bits? If the engine can only look at 32b at a time that would be 20 nodes. Maybe in the ‘worst worst’ case this in theory could happen, but very few ACL rules or Software Defined Network (SDN) software applications specify all of the possible fields for a total of 600b. That is because it is very complex to write a rule which defines all layers of a packet flow including encapsulated sub-flows. And if they did, then an exact match table (binary CAM) like a flow cache is more appropriate than a ternary TCAM. That is why most solutions like P4 and OVS will define packet filters in a hierarchical manner.
MoSys provides a scalable Graph Memory Engine which can be employed in software, FPGA only and FPGA plus MoSys Silicon for solutions from 300M nodes per second to 3B nodes per second. Because the GME RTL has been streamlined, multiple GME engines can be scaled out to have multiple engines in one FPGA. MoSys is developing Adaptation Layer software to generate graphs for IPv4, IPv6 Longest Prefix Match and multi-field matching in support of ACL type packet filtering. Other multi-layer Internet Protocol lookups can be created for more complex applications like DDoS and security applications.
Additional
Resources:
If you are looking for more technical information or need to discuss your technical challenges with an expert, we are happy to help. Email us and we will arrange to have one of our technical specialists speak with you. You can also sign up for updates. Finally, please follow us on social media so we can keep in touch.


