Save 2-8 System Operations with In-Memory Functions (Part 2 RMW)
Thursday May 7, 2020By Mark Baumann
Director, Product Definition & Applications
MoSys, Inc.

In Part I of this blog, we discussed the benefits a feature like BURST brings to system throughput and performance. In Part 2, we will be looking at how the function of a Read-Modify-Write (R-M-W) can also support efficiency and improved throughput.
As mentioned in Part 1, MoSys Accelerator Engines have on-die ALUs which results in the ability of a user to take advantage of a “fire-and-forget” ability. This supports features such as maintenance of statistics, an aging function on table entries, or even handles metering (with two bucket three color capability). All this is handled on the die of the Accelerator Engines as opposed to performing multiple bus transactions in order to Read a location, bring the data back to the host or FPGA, modify the data in the host and then perform a write-back to a location in memory. All these transactions must be scheduled and then executed. By designing the ALU function on the die with the memory, all the back-and-forth between host and memory are minimized to one command and data crossing on the bus. To perform an operation such as a counter update, you simply send the command to update a location along with the location modifier and the Accelerator Engine will autonomously execute the read of the location, modifying the location and write the new result back to the memory.
In addition, the accelerator engines have an additional level of data security. The devices were designed to ensure the integrity of the memory locations. This is handled by covering all memory locations that are used for an R-M-W operation to have EDC. This is known as SECDED (Single error correct double error detect) coverage. What this means is that each location is defined as 64 bits of data and 8 check bits in the 72-bit storage location. This allows MoSys’s Accelerator Engine to insure data integrity by reading a location checking the integrity of the data and if a single bit error is detected then correcting it before modifying the data then generating new check bits to reflect the new data before writing the new data and check bits back into memory. If a double bit error is detected, then no data modification will take place and the host is notified. All these steps are designed to support data integrity and efficient high-speed throughput. In addition, the logic is built-in to support data forwarding which ensures data integrity if multiple back-to-back requests are received to one location.
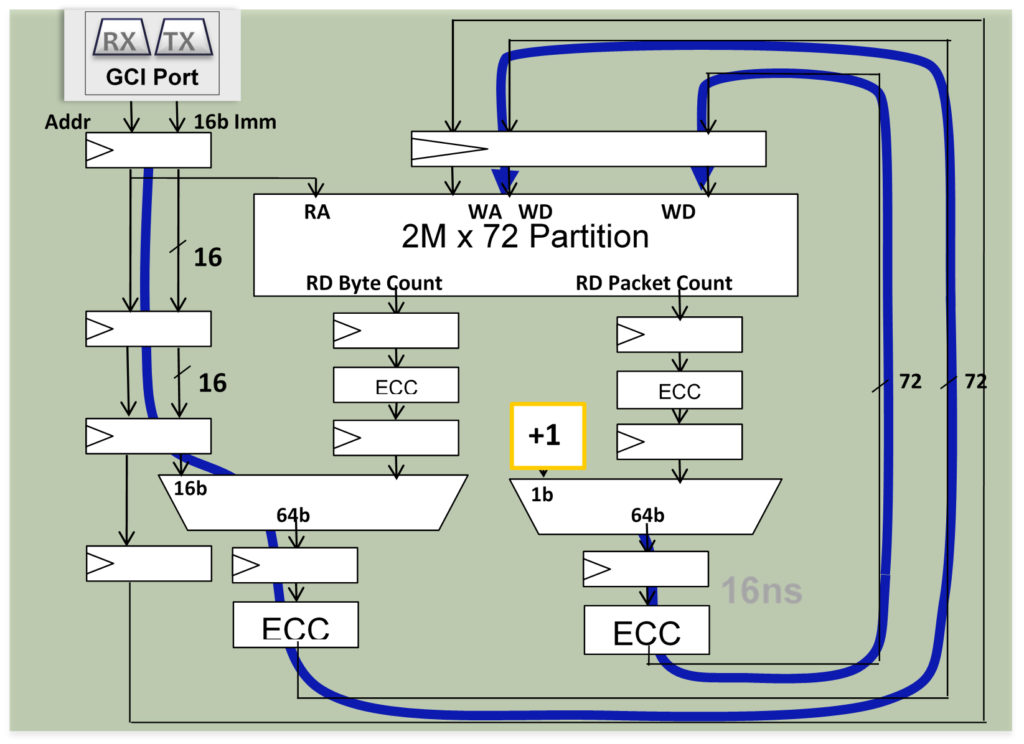
The figure below is a diagram of the flow that is implemented in the accelerator engines for R-M-W operations. It illustrates a fixed pipeline and how ECC is folded into the internal accelerator data path.
- In case of an index match, data is forwarded in the pipeline
- Prevents stale data in the pipeline
- Similar pipeline for Split Counter
- End-to-End ECC Protection
- 16 ns to completion
The following is a list of R-M-W operations available in a BE-3 or PHE device(s):
- Boolean
- AND, OR, XOR memory location with a 16b or 32b mask
- Arithmetic for statistics functions
- Add/Subtract 16b or 32b immediate
- Read and Set 16b, 32b, 64b & double
- Add 1 to packet and 16b or 32b immediate to byte count
- Decrement Age Count of packet/byte counter pair
- Semaphores and Mutex for real-time multi-thread table updates
- Test for Zero and Set on 16b, 32b, & 64b
- Compare and Exchange on 32b
- Specialized counting functions
- Compute running average 16b values
- Compute metering (leaky bucket, 3 color, two rates) for policing and shaping
- AND, OR, XOR memory location with a 16b or 32b mask
The R-M-W functionality is supported in specific devices with this logic. When this function is utilized in a system, it can have the effect of saving multiple system cycles. At a minimum savings, it reduces the R-M-W command cycles from 3 commands to one but, the system savings is most likely significantly higher due to the self-contained, in-memory nature of this operation. Since a second device does not need to get involved with the modify operation, the savings can be significant. It will be entirely dependent on how quickly the host can respond to an external modify request.
As MoSys develops the Accelerator Engine family of products through the Integrated Circuits like the BE-2 and BE-3 devices through the PHE (Programmable HyperSpeed Engine), the benefit continues as support of commonly executed functions in an efficient and minimal overhead cost impact. In the case of the Burst and R-M-W functions, these are also non-complex ways to give system efficiency (save system cycles) back to the system architect.
Additional Resources:
If you are looking for more technical information or need to discuss your technical challenges with an expert, we are happy to help. Email us and we will arrange to have one of our technical specialists speak with you. You can also sign up for updates. Finally, please follow us on social media so we can keep in touch.


