32 Reasons to Love 32 RISC Cores
Wednesday November 20, 2019By Mark Baumann, Director, Product Definition & Applications, MoSys, Inc.
The MoSys PHE accelerator engine comes with 1Gb of memory and 32 RISC cores. Why you ask? We get that a lot. Not the 1Gb of memory but 32 RISC cores. Why would any applications need 32 cores?
First, a little background: In many of the systems that are being designed, there are some very basic goals. The most common system criteria are:
- Speed is critical, this allows for the desired throughput. When attempting to increase the speed of processing it is possible to either increase the clock frequency or multiply the number of processing elements that run in parallel.
- To achieve this speed, it is critical that the processor and memory systems work seamlessly.
- A reasonable power profile must be maintained.
- A reasonable development environment must be available (extended development time can also have a severe impact on achieving system acceptance).
- The Programmable HyperSpeed Engine (PHE) from MoSys address all of these concerns. The memory on the PHE has the speed of SRAM with the density of a specialized DRAM.
The PHE also has 32 RISC cores that are on the same silicon as the 1Gb of memory. This increases the access rate and bandwidth between the memory and processor elements.
The custom RISC cores have been designed to address issues required in data manipulation. This is beneficial in networking, but has advantages in many other fields such as AI, Machine learning, Genomics, etc.
By having memory and processor on a common piece of silicon, a large amount of power is saved by reducing the I/O switching current when going between chips.
This provides an additional benefit of allowing the resources to be specifically targeted to the areas of the system that would benefit the most by have localized processing resources. Also by tuning the number of processing elements used and speed at which they are run can support the desired throughput and power while enabling the system design with room for upgrading, without board re-design.
RISC vs. CISC
Reduced instruction set computer, or RISC, is an instruction set architecture (ISA) that enables fewer cycles per instruction (CPI) as opposed to a complex instruction set computer (CISC). The gist of the idea is that such a computer has a small set of simple and general instructions, rather than a large set of complex and specialized instructions. Another common RISC feature is the load/store architecture, in which memory is accessed through specific instructions rather than as a part of other instructions.
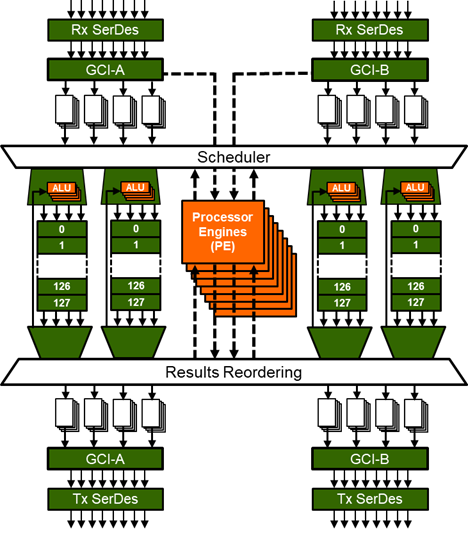
So, the question remains, why 32? Sounds like a lot, which it is. So, below is the count down, the 32 reasons to get 32 RISC cores:
32. Speed.
Speed is critical, this allows for the desired throughput. When attempting to increase the speed of processing it is possible to either increase the clock frequency or multiply the number of processing elements that run in parallel.
31. Single Processor Core.
When looking at what was desirable feature set for a mixed processor, memory device, it was understood that it would be critical to have the processor be capable of performing reads from the memory very efficiently. With the PHE design a single core can support 1.5 B instructions per second.
30. More is Better.
If one core can support 1.5 B instructions, then multiple cores should support (# cores x 1.5B) instructions. It became important to balance the interior device bandwidth with the processing capability. This resulted in the desire to instantiate 32 cores in the MoSys PHE.
29. Balanced Throughput.
With 32 on-board processors it is possible to execute approximately 48-Billion instructions per second. If the PHE is capable of supporting a throughput of 400Gbps in and 400Gbps out . In a network, this type of throughput would equate to 600Mpps. If you correlate the two in an “ideal” scenario that would allow for 80 instructions per packet to be executed to not cause a wait condition. Since we rarely live in an ideal world this can realistically be considered maybe 40 to 50 instructions and allow for some bus contention and not suffer any wait conditions.
28. 48Billion Instructions per Second.
In an ideal case, the 32 cores are running at 1.5GHz, each instruction takes one clock which equates to 48Bips. If we look at the PHE as a processing engine, this will allow a user to operate multiple engines in parallel or sequentially, but with high overall throughput.
27. Multi-Tasking.
When it is desirable to have one functional block perform multiple tasks it quite often requires some programmability. This can either be handled by context switching a processor or having multiple cores that are capable of being programmed independently. This is the approach taken with the PHE. Multiple cores allow for independent operation and functionality.
26. Growth.
In other points it was mentioned that with the addition of each processor element, you can add a potential to execute 1.5 B instructions. This can obviously support a growth in performance of the system, without a board re-design.
25. Flexibility.
As part of the thought process of the PHE, MoSys wanted to ensure that it would support a wide range of both applications and required throughput. This was why the cores within the device are capable of being enabled to increase or decrease performance goals as well as be adaptive to thermal issues.
24. Efficiency.
Utilizing RISC architecture and a custom ISA allows the cores to be efficient for data structures, operate multiple engines in parallel or sequentially, but with high overall throughput.
23. ISA.
The ISA which was designed for the PHE to support data manipulation, with a number of test and branch instructions along with special functions like a HASH and population counts, as examples.
22. Efficient Design.
RISC functions that use only a few parameters are easy to pipeline. By defining the ISA to be focused on data manipulation, the core was designed to be extremely compact and allow for a larger number in a defined area.
21. Saturate the Memory.
To try and utilize as much of the available resources as possible, the available bandwidth is designed to be capable to saturate the memory. If a simple function is believed to take approximately 8 instructions and we are capable of doing 48Bips, then this aligns with our ability to handle 6B reads per second.
20. 6Billion Reads Per Second.
The memory internal bandwidth can support 6Billion reads to the main 1Gb of storage. Balancing access rate and memory bandwidth results in 32 processing elements.
19. RISC Elements.
In utilizing RISC processing elements, which are compact, fast with a defined behavior, allowing for an larger number of Elements to be added.
18. Application Efficiency.
Having 32 processors in one package with the associated memory allows for multiple functions to be executed on the memory without moving it to different subsystems. For example, in a network application you could perform a next hop lookup at the same time another processor could be updating statistics on the packet and a third processor could be developing histograms of the packet flows. All happening concurrently on data that was only transferred once into the PHE device.
17. Board Design Efficiency.
By combining the high-speed memory with the 32 processor cores, it eliminates the board design complexity.
16. IDEm
As a component of the design package an integrated development environment is available for the PHE that supports code design. It is a Linux-based tool that allows for development, assembly and debug (Single step/breakpoint) to simplify development.
15. Future Proof.
32 cores is significant but the PHE is designed to allow you to use only what you need. Using only a few today but in the future using most or all of the available resources.
14. Power.
The number of cores that were designed onto the PHE also had to meet a reasonable power envelope.
13. Die Size.
One of the many goals of the PHE was to make a device that is useful, manufacturable, and within reasonable power limits of a function accelerator.
12. Processor Load Time.
A key design criteria in the development of the PHE, especially due to the fact that the PHE does not use caches, is the time it takes to perform a read or load. The present read times ranges between 6 and 25ns. Since memory access is key to processor performance it was key to balance the load access time and the number of processors that can request data to keep both Memory and processor keep busy.
11. Saves Time, Cost.
The ability to have one die with both a Gb of high speed memory and 32 processing cores eliminates the need for separate devices , board space and design time.
10. No Hassle.
Simpler to use hardware. All the interconnect routing and timing has been resolved to provide the power of 32 RISC cores and attached memory in one device.
9. Less is Best.
By utilizing an architecture that does not rely on caching but is designed to run small highly efficient programs out of local i-mem the cores work efficiently on small repetitive tasks.
8. Learn 1 or 32.
With any new architecture there will be a learning curve. If you go through the effort to learn a new architecture and ISA it will be nice if that same learning can be used to support multiple system configurations. The PHE can span those skews.
7. Targets the Application Type.
When the concept of the PHE was developed, it was realized that there will be many evolving applications but at the core of the process will be the need to manipulate (move, analyze, re-order, count properties, etc.) of the data that is passing through the system. This resulted in the design and flexibility of the PHE.
6. System Efficiency.
By having this much processing power in a single package, it allows a designer to distribute the workload to multiple areas and possibly as close to the edge as desired.
5. Max/Min.
The speed of the operation can be maximized, and the execution time can be minimized, by the combined processor and memory tightly coupled design.
4. Faster.
By having the ability to enable 32 processors the user can utilize concurrent processors to execute multiple streams in parallel or possibly execute multiple threads of a stream concurrently. Resulting in an overall increase performance and throughput.
3. Simplify.
Supporting a complex system design having the resources of 32 RISC cores in a tightly coupled design with 1Gb of fast RAM will simplify board, power, possibly software and system architecture, by allowing simple distribution of processing and placement closer to the edge.
2. Why not 64 Processors?
Although there would be some incrementally beneficial performance that could be gained by adding more cores, this benefit diminishes when the other supporting hardware and does not increase in similar proportion.
1. Just Because.
Because you can. We designed a solution that no one else has been able to design and it allows for all the flexibility and future growth without making the die unmanageable (size or power).